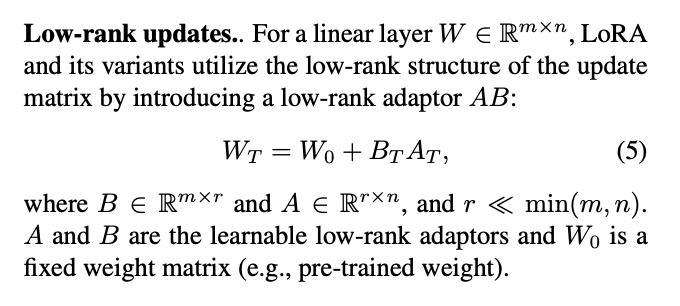1/ I just read the fascinating GaLore paper on memory-efficient LLM training using gradient low-rank projection. Kudos to the authors for this insightful work!
My TL;DR and some thoughts below (as a little paper review) 🧵
2/ GaLore takes a novel approach compared to methods like LoRA and ReLoRA. Instead of doing low-rank projection in weight space (W = W_0 + A@B) and baking this into the weights every T steps, GaLore performs low-rank projection in gradient space: G = P @ G' @ Q^T.
3/ One key aspect of GaLore is that it recomputes the projection matrices P and Q every T steps using the SVD of the full gradient. This allows the low-rank subspace to maximally adapt to the changing gradient distribution during training.
4/ The key design choice for me is that it computes full gradients first and uses them to update the projection matrices every T steps. This means we have only one matrix for the gradients (G) instead of two like in LoRA. Well, P and Q must be stored, but they aren't optimized!
5/ The memory savings in GaLore come from the reduction in optimizer state and the lack of newly introduced weights. In their implementation, they only use P for further savings. This is different from LoRA where the savings only come from the low-rank approx of the weights.
7/ While there are similarities to ReLoRA in terms of alternating between low-rank updates and full-rank updates, the specifics of how it's done in GaLore lead to different (better) training dynamics and memory characteristics.
8/ The adaptive choice of low-rank subspace based on gradient SVD is a particularly novel and promising aspect of GaLore. There are exciting research questions one could work on here.
9/ I'm very excited to see further analysis and extensions of these ideas. The low-rank training landscape is a fascinating area of research with a lot of potential for more efficient LLM training.
1/ I just read the fascinating GaLore paper on memory-efficient LLM training using gradient low-rank projection. Kudos to the authors for this insightful work!
My TL;DR and some thoughts below (as a little paper review) 🧵2/ GaLore takes a novel approach compared to methods like LoRA and ReLoRA. Instead of doing low-rank projection in weight space (W = W_0 + A@B) and baking this into the weights every T steps, GaLore performs low-rank projection in gradient space: G = P @ G' @ Q^T. 3/ One key aspect of GaLore is that it recomputes the projection matrices P and Q every T steps using the SVD of the full gradient. This allows the low-rank subspace to maximally adapt to the changing gradient distribution during training. 4/ The key design choice for me is that it computes full gradients first and uses them to update the projection matrices every T steps. This means we have only one matrix for the gradients (G) instead of two like in LoRA. Well, P and Q must be stored, but they aren't optimized! 5/ The memory savings in GaLore come from the reduction in optimizer state and the lack of newly introduced weights. In their implementation, they only use P for further savings. This is different from LoRA where the savings only come from the low-rank approx of the weights. 7/ While there are similarities to ReLoRA in terms of alternating between low-rank updates and full-rank updates, the specifics of how it's done in GaLore lead to different (better) training dynamics and memory characteristics. 8/ The adaptive choice of low-rank subspace based on gradient SVD is a particularly novel and promising aspect of GaLore. There are exciting research questions one could work on here. 9/ I'm very excited to see further analysis and extensions of these ideas. The low-rank training landscape is a fascinating area of research with a lot of potential for more efficient LLM training.
yes