
We reproduced DeepSeek R1-Zero in the CountDown game, and it just works Through RL, the 3B base LM develops self-verification and search abilities all on its own You can experience the Ahah moment yourself for < $30 Code: https://t.co/UcGKN2SVGj Here's what we learned 🧵

The recipe: We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL. We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number.
The results: It just works! Model start from dummy outputs but gradually develop tactics such as revision and search. In the following sample, the model propose a solution, self-verify, and iteratively revise it until it works. Full experiment log: https://t.co/qNUS8N9X3d

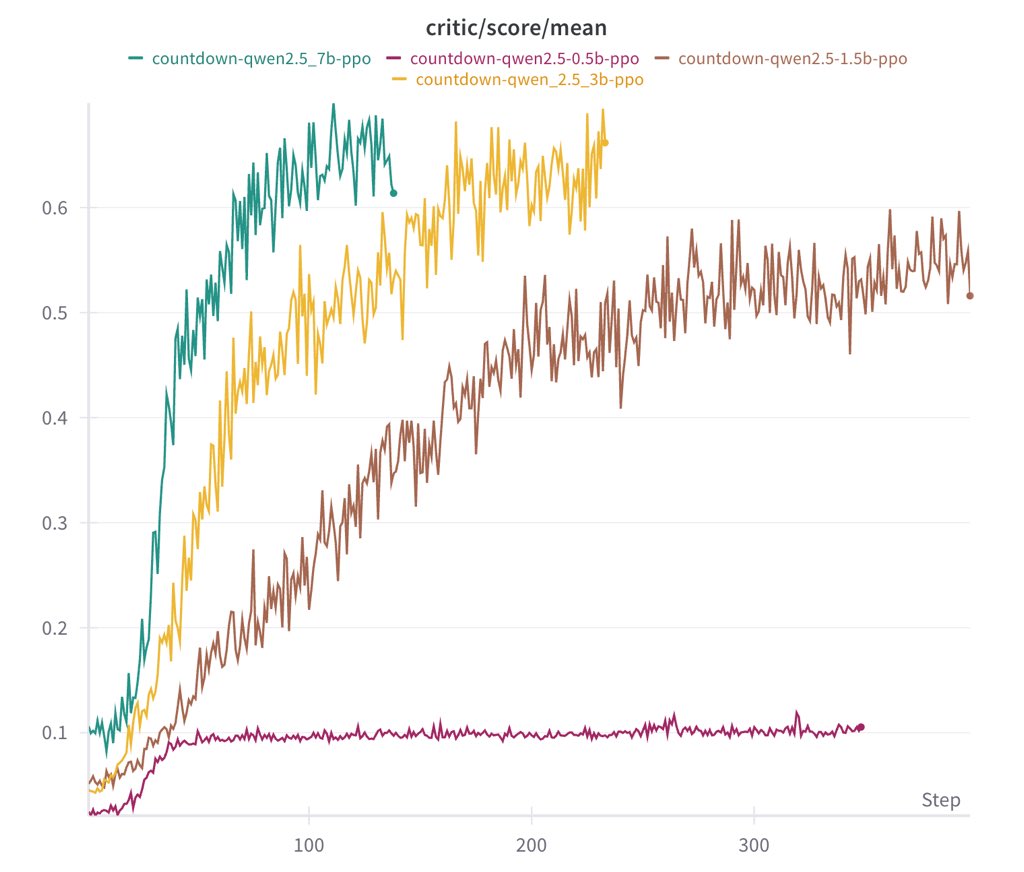
Quick ablations on CountDown: Base model quality is key: We run Qwen-2.5-Base 0.5B, 1.5B, 3B to 7B. 0.5B guess a solution and stop. From 1.5B, the model start learning to search, to self-verify and to revise its solutions, enabling them to achieve much higher scores.
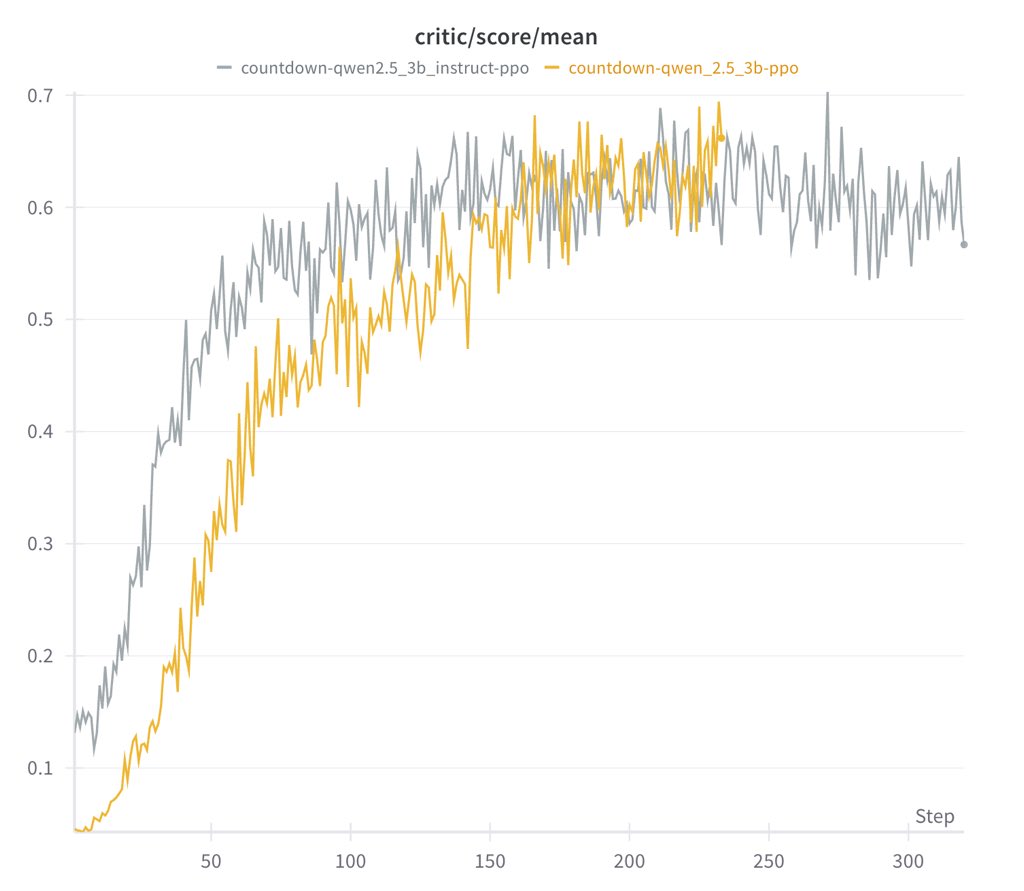
Either base or instruct model works - Instruct model learns faster, but converges to about same performance as base - Instruct model's output are more structured and readable So extra instruction tuning isn't necessary, which supports R1-Zero's design decision
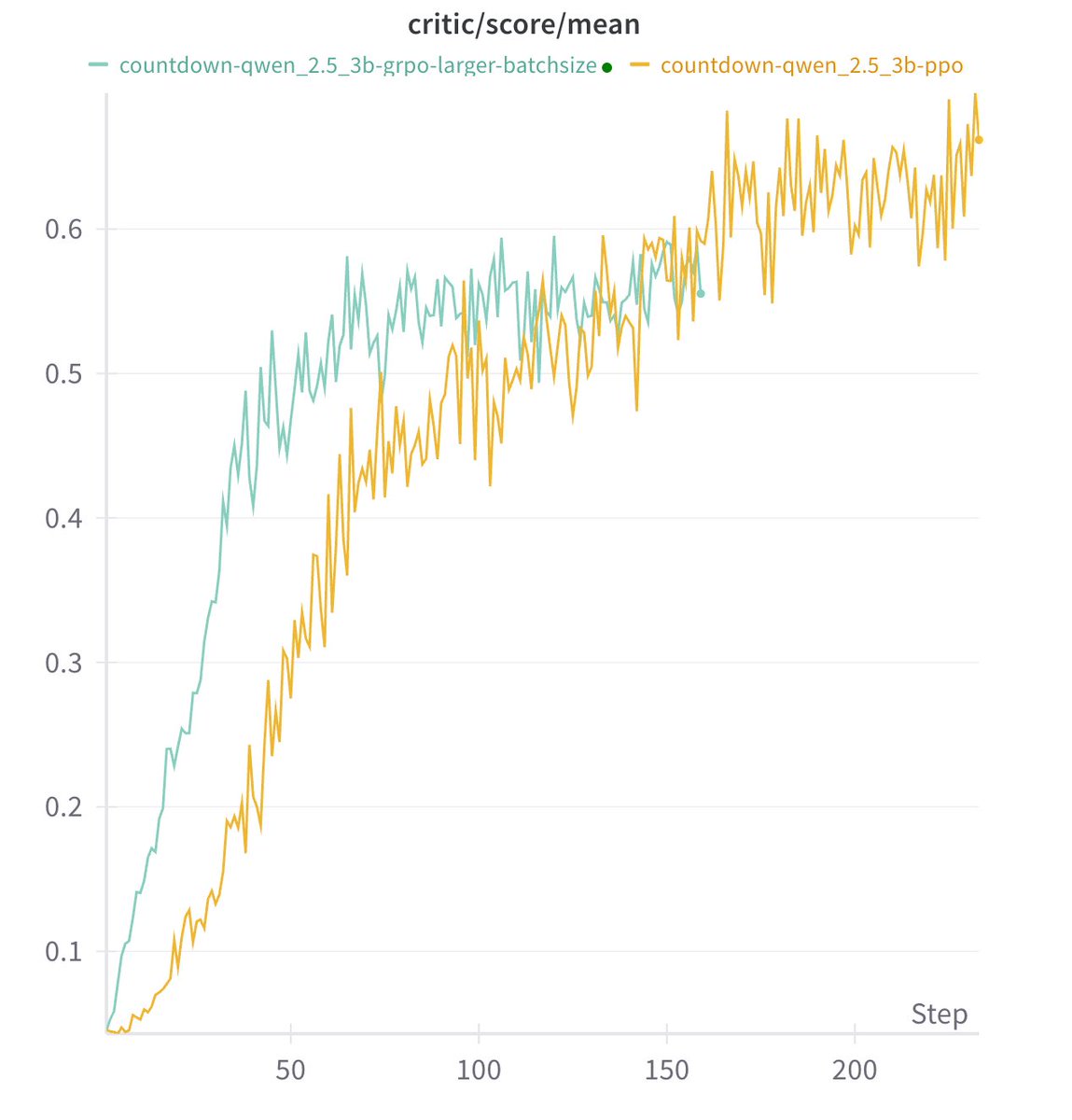
The specific RL alg doesn't matter much We tried PPO, GRPO and PRIME. Long cot all emerge and they seem all work well. We haven't got the time to tune the hyper-parameters, so don't want to make quantitative conclusions about which alg works better.
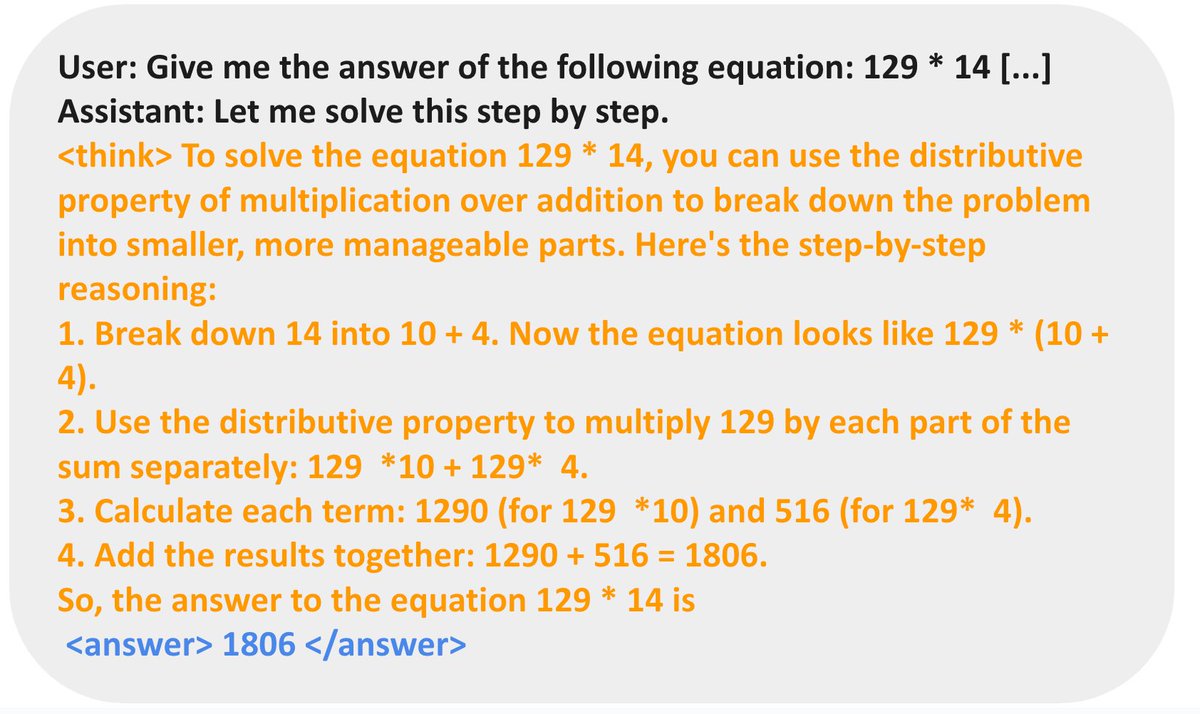
Model's reasoning behavior is very task dependent: - For countdown, the model learns to do search and self-verificatoin - For number multiplicatoin, the model instead learns to break down the problem using distirbution rule and solve it step by step.
Everything's open at https://t.co/QFzjPl7GQB And it costs < $30 to train the model! We hope this project helps to demystify the emerging RL scaling research and make it more accessible!
One caveat, of course, is that it's validated only in the Countdown task but not the general reasoning domain. We are now bounded by compute, and please reach out if you wanna help!
A wild ride with @JunjieZhang12 @xingyaow_ @lifan__yuan